Aug 18 2015
University of Pennsylvania researchers have made strides toward a new method of gene sequencing a strand of DNA’s bases are read as they are threaded through a nanoscopic hole.
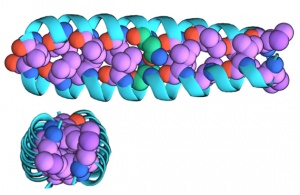 An illustraton of the "zipped" dimer form of GCN4-p1 seen from the side (top) and above (bottom)
An illustraton of the "zipped" dimer form of GCN4-p1 seen from the side (top) and above (bottom)
In a new study, they have shown that this technique can also be applied to proteins as way to learn more about their structure.
Existing methods for this kind of analysis are labor intensive, typically entailing the collection of large quantities of the protein. They also often require modifying the protein, limiting these methods’ usefulness for understanding the protein’s behavior in its natural state.
The Penn researchers’ translocation technique allows for the study of individual proteins without modifying them. Samples taken from a single individual could be analyzed this way, opening applications for disease diagnostics and research.
The study was led by Marija Drndić, a professor in the School of Arts & Sciences’ Department of Physics & Astronomy; David Niedzwiecki, a postdoctoral researcher in her lab; and Jeffery G. Saven, a professor in Penn Arts & Sciences’ Department of Chemistry.
It was published in the journal ACS Nano.
The Penn team’s technique stems from Drndić’s work on nanopore gene sequencing, which aims to distinguish the bases in a strand of DNA by the different percent of the aperture they each block as they pass through a nanoscopic pore. Different silhouettes allow different amounts of an ionic liquid to pass through. The change in ion flow is measured by electronics surrounding the pore; the peaks and valleys of that signal can be correlated to each base.
While researchers work to increase the accuracy of these readings to useful levels, Drndić and her colleagues have experimented with applying the technique to other biological molecules and nanoscale structures.
Collaborating with Saven’s group, they set out to test their pores on even trickier biological molecules.
“There are many proteins that are much smaller and harder to manipulate than a strand of DNA that we’d like to study,” Saven said. “We’re interested in learning about the structure of a given protein, such as whether it exists as a monomer, or combined with another copy into a dimer, or an aggregate of multiple copies known as an oligomer.”
Detection is also often a limitation.
“There are no ways to amplify peptides and proteins like there are for DNA,” Drndić said. “If you want to study proteins from a particular source, you're stuck with very small samples. With this method, however, you can just collect the amount of data you need and the number of proteins you want to pass through the pore and then study them one at a time as they naturally exist in the body.”
Using the Drndić group’s silicon nitride nanopores, which can be drilled to custom diameters, the research team set out to test their technique on GCN4-p1, a protein selected because it contains a common structural motif found in transcription factors and intracellular receptors.
“The dimer version is ‘zipped’ together,” Niedzwiecki said, “It is a ‘coiled coil’ of interleaved helices that is roughly cylindrical. The monomer version is unzipped and is likely not helical; it’s probably more like a string.”
The researchers put different ratios of zipped and unzipped versions of the protein in an ionic fluid and passed them through the pores. While unable to tell the difference between individual proteins, the researchers could perform this analysis on populations of the molecule.
“The dimer and monomer form of the protein block a different number of ions, so we see a different drop in current when they go through the pore,” Niedzwiecki said. “But we get a range of values for both, as not every molecular translocation event is the same.”
Determining whether a specific sample of these types of proteins are aggregating or not could be used to better understand the progression of disease.
“Many researchers,” Saven said, “have observed these long tangles of aggregated peptides and proteins in diseases like Alzheimer’s and Parkinson’s, but there is an increasing body of evidence that is suggesting these tangles are occurring after the fact, that what are really causing the problem are smaller protein assemblies. Figuring out what those assemblies are and how large they are is currently really hard to do, so this may be a way of solving that problem.”
Gabriel Shemer of Drndić’s lab and Christopher J. Lanci and Phillip S. Cheng of Saven’s lab also contributed to this work.
Source: http://www.upenn.edu/